

AI is breaking everything in IT. Once you add highly dense racks of GPUs, network bandwidth often becomes the choke point. Solve that, and further bottlenecks appear — data storage, lack of power to feed the data center, limited power distribution infrastructure within the data center, and inadequate cooling.
At Pure Storage’s Pure//Conference held this month in Las Vegas, the company laid out its vision of high-performance storage for the modern AI enterprise. Robert Alvarez, senior AI solutions architect at Pure Storage, explored the critical role of flash storage in enabling end-to-end AI/ML workflows as a means of ensuring fast, structured access to both raw and transformed data.
“Storage is the least talked about part of AI, yet it has become the lynchpin of AI and analytics performance,” said Alvarez.
Three big AI implementation challenges
He outlined several challenges facing AI implementations.
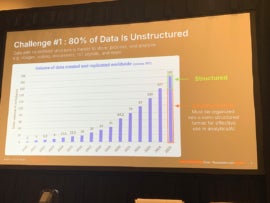
1. Unstructured data
Alvarez cited IDC data that out of 181 zettabytes (ZB) of the total worldwide data that will exist by the end of 2025, 80% of it is unstructured, whereas 10 years ago, only 18 ZB existed. This trend of rapid data growth is expected to continue, with unstructured information representing the bulk of it.
“Having 80% of your data unstructured is a problem for AI,” said Alvarez. “It must be organized into at least a semi-structured format for effective use in AI and analytics.”
2. Cost of adoption
Alvarez said it takes an average of eight months for a generative AI pilot to move from proof of concept to production, according to a Databricks Data + AI Report. Even then, only 48% of AI initiatives achieve full deployment.
“If you rely on NVIDIA GPUs for generative AI, it is likely that supply chain issues will add further to your timeline,” said Alvarez. “A slow ramp-up inflates AI costs.”
Those attempting to build everything in-house from scratch can expect high upfront costs. The adoption of scalable platforms like data lakehouses and real-time processing architectures requires a substantial upfront financial commitment. Alvarez recommended that companies deploying large language models (LLMs) begin in the cloud, use the cloud to flesh out their AI concepts, and then move to an in-house deployment:
- When they have some confidence about what they are trying to do, and
- When cloud costs show signs of rising sharply.
He cited one company that found itself $3 million over its annual AI budget before the end of Q1 due to cloud costs spiraling out of control; that said, he recommended the use of cloud resources when on-prem systems reach their limit. Perhaps there is a sudden peak demand, or a quarterly burst of traffic. Use the cloud to deal with occasional peak demands, as this avoids higher CAPEX spending for in-house systems.
“Data has gravity,” said Alvarez. “The more data you have, and the more you try to use for AI, the more it costs to manage and maintain.”
State of AI maturity
The final challenge is the state of AI maturity, as it’s still a nascent field. Innovation is ongoing at breakneck speed. According to Databricks, there are now millions of AI models available. The number of AI models rose by 1,018% in 2024. Enterprises have so many options that it can be difficult to know where to start.
Those with in-house skills can certainly develop or customize their own LLMs, while everyone else should stick to proven models with a good track record and avoid cloud-forever AI deployments. Alvarez cited another customer example of how the cloud can sometimes be the inhibiting factor to AI productivity.
“The machine learning team took days to iterate on a new model because of AWS access speeds,” said Alvarez.
In this case, switching to on-premise systems and storage streamlined the data pipeline and eliminated most of the cost. He suggested initially deploying cloud resources using the Portworx platform for Kubernetes and container management. When the organization is ready to move to on-prem, Portworx makes the migration much easier.
His main point: Underlying all LLMs and all AI applications is a whole lot of storage. It makes sense, therefore, to deploy a fast, efficient, scalable, and cost-effective storage platform.
“AI is just another storage workload,” said Alvarez. “You use storage when you are reading, writing, and accessing metadata. Just about every workload hits storage; as Pure Storage is agnostic to workloads, we deal with them all very fast.”